Also see: Top 15 Data Warehouse Tools
Just as a warehouse is a large building for the storage of goods, a data warehouses is a repository where large amounts of data can be collected – it’s an important tool for Big Data.
Data warehouses and data warehouse tools have been with us for some time. The father of the data warehouse, Bill Inmon, coined the term more than a quarter of a century ago. He defined the data warehouse as a collection of data to support decision making.
Data warehouses are often associated with large amounts of data. For some, they are measured in 100s of TB, PBs or even Exabytes in some cases. But for others, they can be as small as a TB or less. Data warehouses, then, are not just about size.
What is a Data Warehouse?
According to Greg Schulz, an analyst with Storage and Server IO Group, data warehouses are large repositories for storing and accessing large amounts of data in support of various reporting, business intelligence (BI), analytics, decision support (DSS), research, data mining and other related activities. Data warehouses are optimized to retain and process large amounts of data feed to them via online transactional processing (OLTP) and other systems. This data can then be used for reporting, search and analysis.
What are Data Warehouses Used For?
Databases deal with structured data. Their data is well-defined and well organized. It is organized strictly with each piece adhering to very specific fields. Typically, traditional databases harness OLTP and can process huge volumes of transactions rapidly. A data warehouse, on the other hand, utilizes online analytical processing (OLAP). It typically sits on top of one or more OLTP databases.
A data warehouse, then, is a central repository for an organization’s business information. It can incorporate disparate databases in addition to systems and processes. This facilitates the presentation of a unified and integrated approach to organizing data for better access and easy interpretation. Data warehouse tools make it possible to manage data more efficiently. This includes being able to more easily find, access, visualize and analyze data in order to achieve better business results.
Benefits of a Data Warehouse
An obvious benefit of a data warehouse is that it can host a very large amount of data. High-performance databases don’t need to be cluttered up by an ever-growing volume of stored data, much of it historical. One way to keep them running well and freed up for immediate organizational needs is to offload some data into a data warehouse. In large organizations, multiple databases can feed one large database.
But perhaps the greatest benefit of the data warehouse is the ability to translate raw data into information and insight. The data warehouse offers an effective way to support queries, analytics, reporting, and modeling, as well as forecasting and trending against larger amounts of data and time.
How Are Data Warehouses Constructed?
Data warehouses are optimized to deal with large volumes of data. They are typically housed on mainframes, enterprise-class servers and more recently, in the cloud. Data from OLTP applications and other sources is selectively extracted for use by analytical applications and user queries. Different data warehouses receive and process different types of data. Data volume, frequency, retention periods and other factors determine the specifics of construction.
Even before technology selection and data warehouse design, however, a primary step is to determine business goals and objectives. Based on sound planning, it is important to conduct a data management program and begin collecting, normalizing and cleansing data. This is a vital ingredient if analysis, querying and reporting is to achieve any kind of accuracy.
Design and data cleansing must be supported by the right storage. Generally, data warehouses rely on large storage capacities that have durability, lower cost, and high performance. Older systems might be composed entirely of large collections of Hard Disk Drives (HDDs). But that is changing and data warehouses are appearing as be a hybrid mix of HDDs and solid state drives (SSD). Others are appearing that harness all flash arrays for the highest possible performance.
Additionally, a specific database technology might be selected based on familiarity, cost or time to value. Providers include SAS, Oracle and Teradata.
Data Warehouses versus Data Marts
Another factor to consider is access by users. Some data warehouses are so large that they can become cumbersome for those seeking to use them for analysis, queries and reporting. In such cases, smaller data marts may be split apart for ease of utilization. Data marts can also be used to provide subsets of the data to different user groups. Alternatively, data marts are sometimes established first and then consolidated into a larger data warehouse.
In the top-down approach, data is extracted from disparate systems, cleansed, normalized, summarized and distributed to data marts where users can gain access. In the bottom-up method, the goal is to deliver value as quickly as possible by focusing on the data marts.
There is also a hybrid approach, which tries to blend both methods. It combines the speed of the bottom-up approach without compromising on the data integration benefits of the top-down approach.
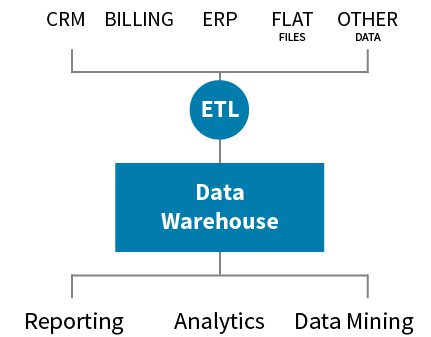
More than yet another tool, the data warehouse is a central element in any Big Data infrastructure.
Disadvantages of Data Warehouses
Data warehouses and data warehouse tools have the disadvantage of primarily dealing with structured data. This leaves the entire field of unstructured data largely outside of their reach. For some, too, data warehouse technology may come with the stigma of being considered old school, dated and therefore not applicable for today’s Big Data and analytics world.
While the technology is still relevant and necessary, perhaps the biggest disadvantage of a data warehouse is that many data warehouse tools were developed decades ago. Some organizations have not updated them with the latest technology, which can dramatically improve functionality. Everything from server upgrades to different data models and new platforms can enable better and faster data access, including self-service data access and data preparation.
Another challenge is that some data warehouses have not kept up with the disruptively low cost of storing data. Newer tools and technologies have evolved such as Hadoop that act as repositories for the ever-growing volume of unstructured data. Similarly, data lakes are evolving which can consolidate multiple stores of unstructured and semi-structured data.
Cost can also be a consideration as some proprietary data warehouse tools can be expensive. But Schulz said that cloud-based and open source data warehouse platforms are becoming available that can accommodate structured and some unstructured data sources. Some have come on the market, for example, with hooks for working with semi-structured or non-structured data. This means that as well as databases, data streams such as video, audio, images and logs may be incorporated in some cases.
A Single Source of Truth
The dream of the data warehouse was to create a single source of truth in the enterprise. However, this goal remained elusive, said Anil Inamdar, Principal Corporate Consultant, Dell EMC Services. He explained that the data being fed into the warehouse came from other systems such as Enterprise Resource Planning (ERP). Additionally, mergers and acquisitions meant that companies would inherit multiple data warehouses that proved difficult to easily consolidate.
“It takes a considerable amount of time to create data warehouses and it has been a challenge to keep in sync with changes to multiple data sources as well as the introduction of newer sources,” said Inamdar.
Data Warehouses versus Data Lakes
Many technologies get labeled as legacy and are thereafter considered outdated. This label was applied, for example, to mainframes which caused them to largely fall out of favor in the nineties. Yet the technology remains relevant and continues to be a mission-critical element inside most large financial institutions.
The same thing could be said about data warehouses. All the hype, these days, is around data lakes and there is much confusion between data lakes and data warehouses. Both are used for data storage, but they take different approaches. Data warehouses adhere to a definite structure whereas data lakes are more fluid. Data lakes hold raw data in its native format. They encompass structured, semi-structured, and unstructured data but without rigid data structure requirements. Inamdar considers data warehouses to now be a subset of a larger data lake ecosystem.
How Does Hadoop Fit In
Hadoop is a data storage option that has gained traction over the last several years. Hadoop, though, does not replace all previous data architectures. Rather than being a data warehouse or a database, it is a file system and a data framework. As such, Gartner research found that less than 5% of companies plan to replace their data warehouse with Hadoop.
The reasons are simple. Replacing a data warehouse from scratch is a massive undertaking. Technologically and culturally, it is not for the faint of heart. That said, Hadoop offers low-cost, high-speed data processing. It can be used to great effect, for example, as a layer on top of a data warehouse.