
In the modern era, enterprise data comes in many forms and is stored in many locations. There is both structured and unstructured data, including rows and columns of data in a traditional database, and data in formats like logs, email, and social media content. Big Data in its many forms is stored in databases, log files, CRM, SaaS, and other apps.
So how do you get an overview of your far-flung data and manage it in all of its disparate forms? You use data virtualization, an umbrella term to describe any approach to master data management that allows for retrieval and manipulation of data without knowing where it is stored or how it is formatted.
Data virtualization integrates data from disparate sources without copying or moving the data, thus giving users a single virtual layer that spans multiple applications, formats, and physical locations. This means faster, easier access to data.
It is the ultimate in modern data integration because it breaks down silos and formats, performing data replication and federation in a real-time format, allowing for greater speed and agility and response time. It helps with data mining, it enables effective data analytics, and is critical for predictive analytics tools. Effective use of machine learning and artificial intelligence is unlikely without data virtualization.
It should be noted that data virtualization is not a data store replicator. Data virtualization does not normally persist or replicate data from source systems. It only stores metadata for the virtual views and integration logic. Caching can be used to improve performance but, by and large, data virtualization is intended to be very lightweight and agile.
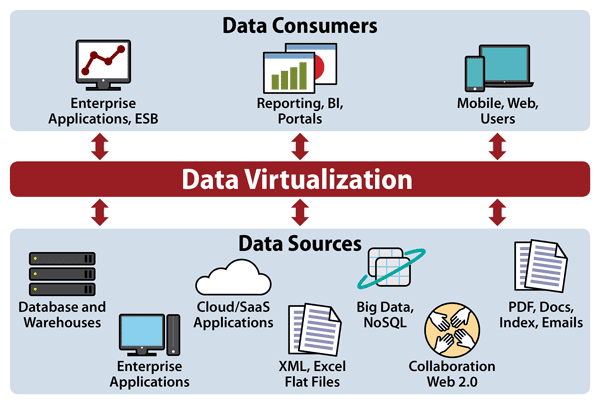
Data virtualization combines data from disparate sources into digestible formats, greatly accelerating the efficiency of data mining.
Data Virtualization Capabilities
Because of its abstraction and federation, data virtualization is ideal for use with Big Data. It hides the complexities of the Big Data stores, whether they are Hadoop or NoSQL stores, and makes it easy to integrate data from these stores with other data within the enterprise. That is the purpose of data virtualization, after all, and Big Data is inherently heterogeneous.
Another benefit to Big Data is something called data warehouse offloading or horizontal partitioning, where older, less frequently accessed data is moved from the data warehouse to cheaper, commodity storage. You might move it from a SSD to hard disk or tape, for example, or in a cloud situation to Amazon Web Service’s Glacier for cold storage.
Data virtualization, then, has a number of capabilities:
- Cost savings: It’s cheaper to store and maintain data than it is to replicate and spend resources transforming it to different formats and locations.
- Logical abstraction and decoupling: Heterogeneous data sources can now interact more easily through data virtualization.
- Data governance: Through central management, data governance challenges can be lessened, and rules can be more easily applied to all of the data from one location.
- Bridging structured and unstructured: Data virtualization can bridge the semantic differences of unstructured and structured data, integration is easier and data quality improves across the board.
- Increased productivity: Aside from the aforementioned bridging of data, virtualization also makes it easier to test and deploy data-driven apps, since less time is needed integrating data sources.
Also keep in mind what data virtualization is not:
- It is not regular virtualization. When the term “virtualization” is used, it typically refers to server hardware virtualization. There is no connection between the two other than the word.
- It is not virtualized data storage, either. Some companies and products use the term data virtualization to describe virtualized database software or storage hardware virtualization products, but they are stand-alone data storage products, not a means of spanning data sources.
- It is not data visualization. The two sound similar but visualization is the display of data in charts, graphs, maps, reports, 3D images, and so on. Data visualization is achieved through data virtualization because it is pulling the data from many different sources.
- It is not data federation. More on this later, but for now, data virtualization and data federation are two different subjects, although some people use the terms interchangeably, which is incorrect.
- It is not a Logical Data Warehouse. LDW is an architectural concept, not a platform. You draw data from a LDW through data virtualization.
- It is not containers. In the contrast between virtualization vs. containers, virtualization is more or an abstract layer, whereas containers are a software-based wrapping for an application and its various supporting components.
Data Virtualization Use Cases
Data virtualization has many uses, since it is simply the process of inserting a layer of data access between disparate data sources and data consumers, such as dashboards or visualization tools. Some of the more common use cases include:
Data Integration
This is the most likely case you will encounter, since virtually every company has data from many different data sources. That means bridging an old data source, housed in a client/server setup, with new digital systems like social media. You use connections, like Java DAO, ODBC, SOAP, or other APIs, and search your data with the data catalog. The hard part is more likely to be building the connections, even with data virtualization.
Logical Data Warehouses
The logical data warehouse is similar in function to the traditional data warehouse, with a number of exceptions. For starters, unlike a data warehouse, where data is prepared, filtered, and stored, no data is stored in a LDW. Data resides at the source, whatever that may be, including a traditional data warehouse. Because of this no infrastructure is needed; you use the existing data stores. A good LDW package federates all data sources and provides a single platform for integration using a range of services, like SOAP, REST, Odata, SharePoint, and ADO.Net.
Big Data and Predictive Analytics
Again, the nature of data virtualization works well here because Big Data and predictive analytics are built on heterogeneous data sources. It’s not just drawing from an Oracle database, Big Data comes from things like cell phone use, social media, and email. So data virtualization lends itself to these highly diverse methodologies.
Operational Uses
One of the great headaches for call centers or customer service applications is siloed data, and for a long time, it remained that way. A bank would need a different call center for credit cards than for home loans, for example. With data virtualization spanning the data silos, everyone from a call center to a database manager can see the entire span of data stores from a single point of access.
Abstraction and Decoupling
This is the flip side to all of the unification features discussed above. Perhaps there are data sources you want to isolate, either due to questionable sources, privacy rules, or other compliance regulations. Data virtualization lets you isolate a particular data source from certain users who should not have access to that data.
Data Virtualization: Related Topics
Data Virtualization vs. Data Federation
These two terms are often used interchangeably, which is an error. Data federation is a type of data virtualization. Both are techniques designed to simplify access for applications to data. The difference is that data federation is used to provide a single form of access to virtual databases with strict data models. Data virtualization doesn’t use a data model and can access a variety of data types.
Data Virtualization vs. Data Lake
Data virtualization and data lakes are not competitors nor should they be confused. A data lake, which is just a massive repository of unprocessed, unstructured data, is one of the many data sources you connect in a data virtualization environment. (By the way, it’s also helpful to understand the date lake vs. data warehouse difference.)
Data Virtualization vs. Data Integration
Data integration is something you do and data virtualization is the means to get there. Integration, as the name implies, is the process of combining data from a heterogeneous data stores to create a unified view of all that data. You use data virtualization to bridge the different data silos, then perform the joining, transforming, enriching, and cleaning of the data before integrating it into a dashboard or some other visualization methodology.
Data Virtualization Architecture
Data virtualization solutions need to be agile in order to adapt to changing requirements across the organization. New data sources will be constantly added and some removed. And as you add more sources, the risk of complexity and slow scaling will emerge. Plus you may have overlapping code adding unnecessary complexity. To avoid all of this, keep the following in mind:
- Build your applications with a layered approach to isolate business logic and transformation components.
- Have strict rules for standards like naming and for reusability and layer isolation.
- Use data virtualization modeling tools like PowerDesigner, TIBCO Data Virtualization, Cisco Data Virtualization, and Oracle Data Service Integrator.
- Involve the data architecture, data security, and data governance teams from the start to build the data connectors in full regulatory compliance
- Determine who has what responsibilities for the data virtualization platform.
Data Virtualization Tools
Data virtualization platforms are all designed to span disparate data sources through a unified interface, but they all get there by a different route. A few big names have gotten into the market but since left. These include Cisco, which sold off its data virtualization product to TIBCO in 2017, and IBM, which got into the market with a big splash in 2014 but no longer sells IBM SmartCloud Data Virtualization.
Here is a list of the better known data virtualization products.
DataCurrent – Places emphasis on data stored in NoSQL repositories, cloud services and application data as well as supporting business intelligence tools to connect to these data sources.
Denodo – Specializing in real-time data, Denodo is known for being easy to learn and use.
Oracle Data Service Integrator – Powerful data integrator that works best with Oracle products/
Red Hat JBoss Data Virtualization – Written in Java, works best with any JDBC interface. ODBC is said to be lacking.
SAS Federation Server – Places great emphasis on securing data.
TIBCO Data Virtualization – Known for connecting to a wide variety of data sources
{kind=link}