Also see: Top 15 Data Warehouse Tools
The term “Data Lake” has been growing in popularity as one of the big new buzzwords surrounding Big Data, and for those of you who have invested decades into building one or more data warehouses, youc may be wondering if this means starting all over from scratch.
Well, nothing could be further from the truth. Data Lakes and Data Warehouses are two very different concepts that are quite capable of co-existing and working together quite effectively. Both are capable of providing business insight and information to run your business. You just need to learn the key differences and how their synergy works.
The only commonality between the two is that they are both data storage repositories. That’s it.
What is a Data Lake?
A data lake is a storage repository that holds a vast amount of raw data in its native format and stores it unprocessed until it is needed. A data lake uses a flat architecture to store data so the data is completely unstructured and left in the format in which it was originally ingested, although each data element in the lake is assigned a unique identifier and tagged with a set of extended metadata tags. That way when a query is run, it can be run against a smaller set of data with the specific tags rather than processing all of the data in the lake.
What is a Data Warehouse?
The opposite of a data lake, a data warehouse is a hierarchical, structured data repository of integrated data from multiple sources, organized for creating analytical reports. They often use multiple databases for different types of data storage, such as ingestion, staging, and transformation, and for processing, such as online analytical processing or online transaction processing.
So to break down the differences:
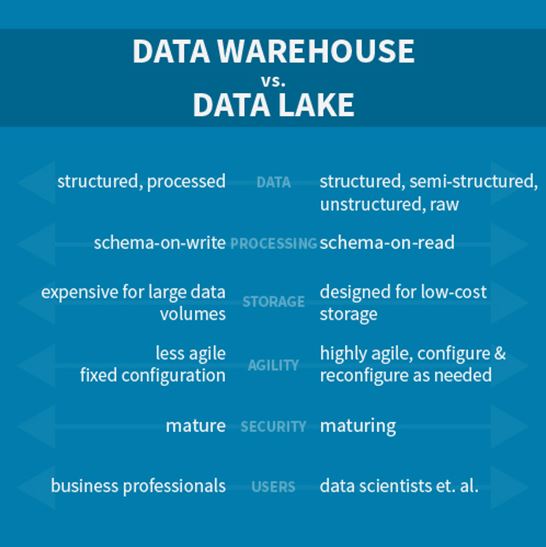
- Data: A data warehouse stores data that has been structured, while a data lake uses no structure at all.
- Processing: Data is processed before it is loaded into a data warehouse to give it some kind of model. With the data lake, you have raw data, as-is, and you process it when you need to.
- Storage: Data warehouses tend to be on large, mission critical systems running massive databases, whereas data lakes are run on Hadoop, which is designed for low-cost, scale out hardware.
- Repurposing: A data warehouse is a highly-structured repository, so it doesn’t respond well to change. It can be done but it takes time. A data lake lacks any kind of structure so it can be configured and reconfigured on the fly as needs change.
Though both are storage repositories, a data warehouse and data lake are very differerent structures.
Data Lake vs. Data Warehouse: How to Choose
How do you choose between the data lake or a data warehouse? Start by not thinking that way. “You should never choose one or the other. The two complement each other. They have different SLAs and use cases,” said Mark Beyer, research vice president and distinguished analyst for Data and Analytics at Gartner.
Business analysts make up 90% of the data warehouse users and don’t need a lake, the warehouse suits their needs by providing business reports. It’s the remaining 10% who need both the lake and warehouse, he said, for more exploratory queries, since the lake is more flexible in searches.
“There is no time when you don’t need a lake. The data warehouse is for high performance, repeatability, constant use. The data lake is for explorations, innovation, flexibility. That’s their focus. I can do both jobs with either. The question is should you,” said Beyer.
Wei Zheng, vice president of products at Trifacta, a data preparation software vendor, said once Hadoop and Big Data came around, people tried to offload data warehousing duties into data lakes but that was more a tactical effort to save costs.
“It’s still happening, it’s probably accurate to say because there was no alternative, they were stuffing every bit of data they got into a data warehouse. Now that there is this data lake architecture there is an opportunity for companies to rethink their data architecture. That’s not to say it’s a replacement for the warehouse. There are differences between the two architectures and both are valid,” she said.
What has happened in the market is the data lake is trying to catch up to all the things the warehouse has been able to do since 1989, when it first appeared, through a 35-year evolution. Data lakes, for example, need security management, optimizing techniques, workload management, distribution processes, while the databases in data warehouses can do all that, notes Beyer.
“A data lake is more flexible because the environment is not tuned for performance, although they can, but if it’s a relational data warehouse that thing has been tuned for performance for 35 years,” he said. “In the Hadoop world, they have around four years of experience of trying to figure out all the different use cases.”
The use case comes down to what you want out of the data. If you know what you are looking for – monthly sales reports, in-store vs. Website traffic, etc. – then the warehouse is suited for you. If you want search for something more amorphous, like what time of day you get the most traffic, or how weather patterns impact sales, then the lake is what you want, said Zheng.
“The person that is the report builder is not responsible for massaging the data into the schema in the warehouse. ETL or data integration is done by a technical user in IT. In a data lake architecture and who consumes it, typically it’s a business user that wants to be able to self-service. The massaging of the data now is done soup to nuts ideally by a business user,” she said.
So to sum it up, the differences between the two data stores are:
Data Warehouse
- Repeatable, reusable, for high performance data questions
Data Lake
- Discovery, learning more about the data, and scaling out for users who know how to write their question
Another Point of View on Data Lakes and Data Warehouses
While some say you should have both a data lake and a data warehouse, Joshua Greenbaum, principal analyst with Enterprise Applications Consulting, thinks you shouldn’t have either.
“Most companies building data lakes thought they needed to accumulate as much data as possible in one place as before you can analyze it. False,” he said. “Just because you accumulate a lot of data doesn’t mean you’ve created anything useful. The more data you accumulate, the more chances for data quality and data governance problems, and it’s a guarantee you will have both.”
No one should do a Big Data project, he argues, they should be doing projects around business outcomes and objectives, which are then used to figure out the appropriate data to figure the appropriate outcome and determine what data needs to be gathered.
“Most of the companies I work with are tempted to make that mistake because they think to solve Big Data problems you need lots of data, and data by itself is useless. Companies need to stop looking at this as a quantity issue and look at it as a quality and outcome issue. You want to better at a process. You start with figuring out what you want to do and figure out what you data need to accomplish it. That’s the only way you can have a successful Big Data project,” he said.